Spring Boot 4 + OpenTelemetry: del Java agent a la integración nativa

Alejandro Alonso Noguerales
28 may 2026
En la primera parte de la serie hablé del concepto: las tres señales, OpenTelemetry como estándar, la promesa de “instrumenta una vez, elige backend después”. Todo muy claro en pizarra.
Cuando tocó montarlo en el ERP, la realidad fue otra. La integración funcionaba, pero había varias decisiones intermedias que el quickstart oficial no aborda. Y al llegar al backend descubrí algo que el discurso de OTel anticipa pero que cuesta ver hasta que lo pruebas: las apps ya no se enteran de cuál es. El mismo demo arranca contra ELK o contra el stack OSS de Grafana sin tocar una línea de Java.
Este post va de eso. Cómo se traza una petición HTTP y un mensaje de Kafka en Spring Boot 4 con la integración nativa de OpenTelemetry, qué hay que configurar a mano más allá del starter, y cómo se ve el mismo flujo en los dos backends más habituales — para que la elección entre ellos sea operativa (familiaridad del equipo, licencia, ecosistema), no técnica.
01 — Del Java agent a la integración nativa
Mi primer intento con OpenTelemetry fue hace más de un año, con Spring Boot 3. La forma “oficial” de instrumentar era el Java agent de OpenTelemetry: un JAR que se descarga, se engancha como parámetro -javaagent al arrancar la JVM, y se encarga de inyectar instrumentación en el bytecode de las librerías sobre la marcha.
Funcionaba. Se veían trazas, métricas y logs correlacionados. Pero había varias cosas que me chirriaban.
La primera era el modelo en sí: una pieza externa al artefacto, descargada aparte, que modifica el bytecode de la aplicación en runtime. La técnica está madura — se lleva usando años en agentes de APM comerciales — pero implica que el jar y la observabilidad viven en realidades separadas. El día que algo falla, toca pensar si el problema está en el código propio o en lo que el agent le ha hecho a ese código.
La segunda era operacional. El agent es un binario que hay que mantener actualizado por separado. Versiones que cuadren con la JVM, con Spring Boot, con las librerías instrumentadas. Una pieza más en el inventario, otra cadena de dependencias que vigilar.
La tercera era de configuración. El agent se controla por variables de entorno o por un fichero de propiedades aparte. Querer condicionar comportamiento por entorno — no exportar en local, exportar agresivamente en pre, samplear en producción — acababa en scripts de arranque distintos por entorno.
Spring Boot 4 introdujo spring-boot-starter-opentelemetry. Una dependencia más en el pom.xml. Configurable como cualquier otro starter, con application.yml, profiles, propiedades condicionales. El agent desaparece. La instrumentación viene de librerías Spring que se enganchan en los puntos de extensión que la propia Spring ya tenía para Micrometer.
02 — Dos patrones cubren casi todo
Cuando empecé a trazar el ERP, lo primero que vi es que dos patrones cubren el grueso del tráfico:
-
Una petición HTTP entra y sale. Un controller recibe la petición, llama a servicios, quizá hace una query a base de datos, devuelve una respuesta. Todo dentro del mismo proceso, todo dentro del mismo thread (o casi, si se usan virtual threads o async). La traza es lineal.
-
Un mensaje de Kafka cruza entre procesos. Un producer publica un evento, el consumer lo recibe en otra JVM y procesa. Aquí la traza tiene que saltar de un proceso a otro a través del broker, que es donde la propagación del contexto pide más cuidado — y donde el demo necesita un parche concreto del lado consumer, como veremos en la sección 04.
Llamadas REST entre servicios, JDBC, JPA, Redis — todo es variación del primero. Llamadas asíncronas, RabbitMQ, SQS — variación del segundo.
Hay casos que no encajan limpiamente en ninguno de los dos: @Scheduled, SSE long-lived, WebSocket, Spring Batch. Existen — en nuestro propio ERP los tenemos — y o reducen a uno de los dos por debajo (SSE es HTTP, el handshake del WS es HTTP), o requieren instrumentación manual para verlos con el mismo detalle. Por eso este post se centra en HTTP y Kafka: son los dos patrones que cubren la mayoría del código que se escribe y donde el demo enseña algo aplicable directamente. Los demás los recojo en la sección 09.
Para enseñar los dos en un mismo artículo, monté una demo con dos servicios Spring Boot 4 conectados por Kafka vía Spring Cloud Stream:
order-api: recibePOST /orders, expone unSupplier<Flux<Message<Order>>>que el binder enchufa al topicorders.created. El controller empuja al sink reactivo.order-processor: expone unFunction<Message<OrderMessage>, Message<ProcessedEvent>>que el binder conecta aorders.created(entrada) y aorders.processed(salida). Una sola función para consumir, persistir y emitir el evento procesado.
Toda la demo está en un repo público, con docker compose para arrancarla en local. El enlace está al final del artículo.
03 — Lo que el starter da gratis
El starter de OpenTelemetry para Spring Boot 4 instrumenta automáticamente las piezas más comunes:
- Servidor HTTP: cada petición entrante crea un span padre con método, ruta, status code y duración. Si el cliente envía
traceparent(header W3C estándar), se enlaza con la traza existente; si no, abre una nueva. - Cliente HTTP (RestClient / WebClient): cada llamada saliente crea un span hijo y propaga el
traceparentautomáticamente al servicio destino. - JDBC / JPA: cada query es un span con el SQL ejecutado (configurable cuánto detalle).
- Kafka producer: con
spring.cloud.stream.kafka.binder.enable-observation: true, cadasend()inyecta el header W3Ctraceparenten el mensaje. Sin esta flag, los spans del producer existen pero el header no viaja con el mensaje. La sorpresa más grande del montaje fue darme cuenta de que el consumer-side no es simétrico — lo explico en la sección 04, en “Propagación consumer-side por Kafka”. - Métricas de JVM: heap, GC, threads, classloader. Las que Micrometer ya emitía, pero ahora en formato OTLP.
- Logs: si se configura el Logback appender (sección 04, “Instalar el appender de Logback a mano”), cada log queda enriquecido con
trace_idyspan_idautomáticamente.
Para activar todo esto, dos cosas en el pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-opentelemetry</artifactId>
</dependency>Y un bloque mínimo en application.yml:
spring:
application:
name: order-api
cloud:
stream:
kafka:
binder:
enable-observation: true
otel:
exporter:
otlp:
endpoint: http://otel-collector:4318A los pocos segundos del arranque ya se están emitiendo trazas, métricas y logs por OTLP al Collector. Sin agent, sin scripts de arranque, sin configuración mágica.
04 — Lo que hay que configurar a mano
Lo de arriba es lo que cuenta cualquier tutorial. Pero quedan varios detalles que solo se descubren al llevar la integración a un sistema real.
Cuántas dependencias OTel necesitas (spoiler: menos de las que crees)
La primera tentación al leer la documentación de OTel es añadir un montón de librerías: opentelemetry-api, opentelemetry-sdk, opentelemetry-runtime-telemetry-java17, opentelemetry-exporter-otlp, opentelemetry-logback-appender-1.0, opentelemetry-jdbc, opentelemetry-spring-kafka… La realidad: con Spring Boot 4 te bastan tres y solo una de ellas requiere atención:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-opentelemetry</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-otlp</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-logback-appender-1.0</artifactId>
</dependency>¿Y las métricas runtime de la JVM? Las emite Micrometer, que ya viene con Actuator y que el starter conecta al SDK de OTel sin que tengas que añadir nada. Comprobado mirando los documentos en Elasticsearch: las métricas jvm.memory.used, jvm.threads.live, process.cpu.usage salen todas con telemetry.sdk.name: io.micrometer. Añadir opentelemetry-runtime-telemetry-java17 es duplicar la misma información con otro nombre.
¿Y la instrumentación JDBC, Spring Kafka, etc.? Spring Boot ya las trae conectadas via observation. Solo añades librerías OTel cuando hay una pieza para la que no hay equivalente en Micrometer/Observation.
El único punto delicado: alinear versiones del bridge Logback
De las tres dependencies, solo una (opentelemetry-logback-appender-1.0) está en alpha y requiere un detalle adicional: depende de opentelemetry-api 1.61.0, pero Spring Boot 4.0.6 fija 1.55.0. Resultado: NoSuchMethodError en GlobalOpenTelemetry.getOrNoop() en cuanto arranca la app.
La solución es importar el BOM de instrumentación antes del BOM de Spring Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-instrumentation-bom-alpha</artifactId>
<version>2.27.0-alpha</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>Cuando Spring incluya el appender de OTel en el propio starter (es donde está claramente yendo el roadmap), la dependencia y el BOM dejan de hacer falta. Hasta entonces, este es el mínimo que necesitas.
Propagación consumer-side por Kafka: hay que extraerla a mano
El producer inyecta traceparent en el header del mensaje cuando se activa enable-observation en el binder. Hasta aquí, perfecto. Pero el consumer-side de Spring Cloud Stream Kafka en spring-cloud 2025.1.1 no extrae ese header al contexto OTel automáticamente.
Lo comprobé probando todas las flags razonables: spring.kafka.template.observation-enabled, spring.kafka.listener.observation-enabled, spring.cloud.stream.kafka.binder.enable-observation, spring.cloud.function.observation-enabled, spring.cloud.stream.bindings.<x>.consumer.observation-enabled. Ninguna hace que el consumer abra el span con el traceparent del mensaje como parent. Resultado: cada mensaje arranca una traza nueva, y se pierde la correlación distribuida.
La solución temporal es extraer el contexto a mano dentro del Function:
@Bean
public Function<Message<OrderMessage>, Message<ProcessedEvent>> orderConsumer(OpenTelemetry openTelemetry) {
return inputMessage -> {
Context extracted = openTelemetry.getPropagators()
.getTextMapPropagator()
.extract(Context.current(), inputMessage.getHeaders(), HEADER_GETTER);
try (Scope ignored = extracted.makeCurrent()) {
// procesamiento; al ser una Function, el mensaje devuelto
// se publica al binding -out-0 (orders.processed) heredando
// este contexto.
return MessageBuilder.withPayload(...).build();
}
};
}Donde HEADER_GETTER es un adaptador TextMapGetter<MessageHeaders> de 10 líneas que lee del Spring MessageHeaders en vez del Map<String, String> que OTel espera por defecto.
Con esto, los spans que se creen dentro del scope (JPA, el producer del siguiente topic) heredan el trace_id correcto. La traza distribuida vuelve a estar viva.
Es feo y debería desaparecer cuando esta carencia se solucione upstream — pero hoy es la única forma fiable que he encontrado. Vale la pena el bloque de seis líneas a cambio del trace completo.
El trace_id en los logs antes de que OTel arranque
El starter mete trace_id y span_id en el MDC de cada log… cuando hay una traza activa. Pero hay un montón de momentos en los que una aplicación logea sin haber pasado por un controller HTTP o un consumer de Kafka: el arranque, tareas programadas con @Scheduled, jobs de inicialización, logs de configuración.
Esos logs salen sin trace_id. Y cuando hay que diagnosticar algo que pasa durante el arranque o en una tarea programada, vuelve a ser como antes: filtrar por timestamp y rezar.
La solución en el ERP fue un filtro propio, CorrelationIdFilter, que se encarga de poner siempre algo en el MDC desde el momento más temprano posible:
- Si la petición trae un header
X-Correlation-Id, se usa ese. - Si hay un
trace_idya activo (OTel ha entrado antes), se usa ese. - Si no hay nada, se genera un UUID nuevo.
Ese filtro corre antes que cualquier otro filtro Spring. Es el primero en tocar el request. Con esto, cualquier log que salga durante el procesamiento de una petición tiene siempre un identificador con el que correlacionar, venga de OTel o no.
Por qué importa: en producción hay peticiones que vienen de fuera con sus propios trace IDs (otros equipos, gateways), peticiones internas que sí van por OTel, y peticiones de health checks que no se quieren trazar. Un solo mecanismo no cubre los tres casos. Este filtro sí.
Instalar el appender de Logback a mano
El starter no instala automáticamente el OpenTelemetryAppender de Logback. Está disponible, pero hay que conectarlo a mano. En el logback-spring.xml:
<appender name="OTEL" class="io.opentelemetry.instrumentation.logback.appender.v1_0.OpenTelemetryAppender">
<captureExperimentalAttributes>true</captureExperimentalAttributes>
<captureMdcAttributes>*</captureMdcAttributes>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="OTEL"/>
</root>Y en el código, registrar el appender contra el OpenTelemetry global cuando la aplicación arranca:
@Bean
public ApplicationRunner installOtelLogAppender(OpenTelemetry openTelemetry) {
return args -> OpenTelemetryAppender.install(openTelemetry);
}Sin esto, los logs salen por consola pero no se exportan a OTLP. Es fácil pasarse un buen rato preguntándose por qué Kibana no recibe nada antes de caer en este detalle.
Capturar excepciones para que la pestaña Errors no quede vacía
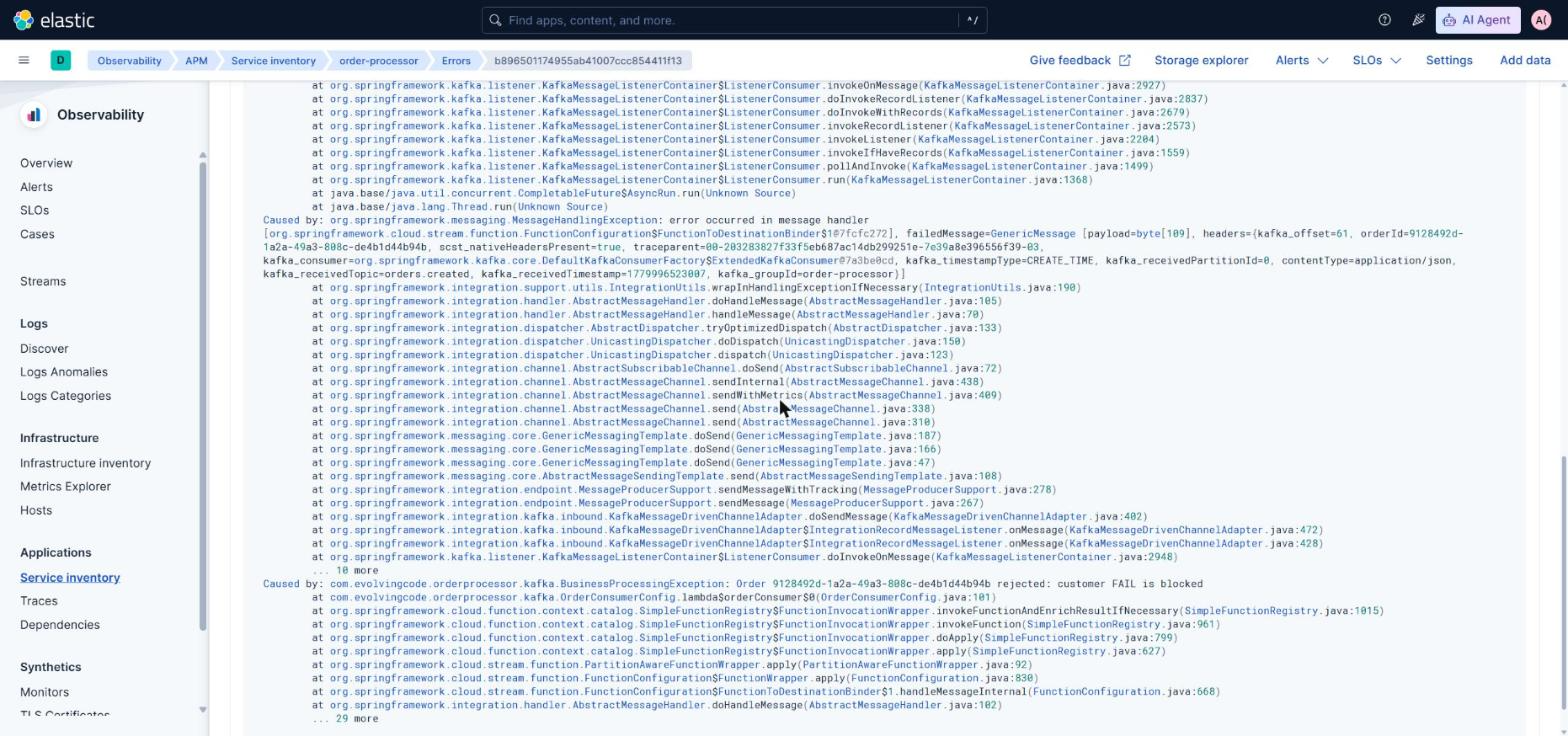
El starter instrumenta el servidor HTTP y abre un span por cada petición. Si el controller lanza una excepción que escapa al servlet container, ese span termina con status=ERROR y la traza queda marcada como fallo. Bien.
Pero hay un caso muy común que NO funciona: cuando un @RestControllerAdvice o cualquier @ExceptionHandler captura la excepción y devuelve un ResponseEntity. Spring resuelve el error internamente, el filtro de OTel ve un 400 limpio, y el span termina con status=UNSET. La pestaña APM Errors de Kibana — o equivalente — se queda vacía aunque la aplicación esté lanzando excepciones a mansalva.
El fix es tres líneas en el handler global: registrar la excepción manualmente en el span actual antes de devolver el response.
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<...> handleValidation(MethodArgumentNotValidException ex) {
Span span = Span.current();
span.recordException(ex);
span.setStatus(StatusCode.ERROR, ex.getClass().getSimpleName());
return ResponseEntity.badRequest().body(...);
}
@ExceptionHandler(Exception.class)
public ResponseEntity<...> handleAny(Exception ex) {
Span.current().recordException(ex);
Span.current().setStatus(StatusCode.ERROR, ex.getClass().getSimpleName());
return ResponseEntity.status(500).body(...);
}
}recordException() añade un span event con la clase, el mensaje y el stack trace; setStatus(ERROR) marca el span como fallo. Lo que el processor elasticapm del Collector necesita para emitir el documento APM error que rellena la pestaña Errors, con error.grouping_key y stack trace navegable. En Grafana, exactamente lo mismo: el panel “Errors by span” se llena con los spans que tienen status.code=STATUS_CODE_ERROR.
Lo mismo aplica al consumer de Kafka. Cuando el Function lanza una excepción, hay que registrarla a mano antes de relanzar, o el ListenerExecutionFailedException con el que Spring Kafka la envuelve llega sin stack trace al backend:
try {
// procesamiento...
return MessageBuilder.withPayload(result).build();
} catch (RuntimeException ex) {
Span span = Span.current();
span.recordException(ex);
span.setStatus(StatusCode.ERROR, ex.getClass().getSimpleName());
throw ex;
}
Es una de esas piezas que el quickstart asume pero ningún ejemplo muestra. Sin ella, las trazas existen pero la pestaña Errors queda como decoración.
Métricas de negocio: el mismo bus que las de la JVM
El starter conecta Micrometer al SDK de OTel para las métricas runtime: heap, threads, GC, http server requests. Lo que no es tan evidente es que cualquier métrica que tú emitas via Micrometer viaja por el mismo bus. No hace falta otra librería, no hace falta MeterProvider aparte. Un Counter Micrometer con la API de toda la vida sale por OTLP igual que jvm.memory.used.
En el demo, cada llamada al endpoint emite un contador con la etiqueta del outcome:
@Autowired MeterRegistry meterRegistry;
@PostMapping
public Map<String, Object> create(@Valid @RequestBody CreateOrderRequest req) {
// ... publish to Kafka ...
Counter.builder("orders.created.total")
.tag("outcome", "accepted")
.register(meterRegistry)
.increment();
return Map.of("orderId", id, "status", "ACCEPTED");
}Y desde el @ExceptionHandler, con outcome invalid_payload, malformed_json, server_error. Cinco minutos de código que aparecen en Prometheus o Elasticsearch — según el backend que esté detrás — como orders_created_total{outcome="accepted", service_name="order-api", ...}, con todos los resource attributes que ya llevan las otras métricas.
Dos cosas a tener en cuenta:
- La cardinalidad la pones tú. El atributo
outcometiene cuatro valores; es seguro. Si en su lugar pusierascustomer_idoorder_idcada combinación abriría una serie temporal nueva y el cluster acabaría reventando en semanas. La regla es simple: identificadores únicos solo en spans y logs, nunca como atributos de métrica. - El nombre se normaliza al exportar.
orders.created.totalen Micrometer aparece comoorders_created_totalen Prometheus por el separador de namespaces. En Elasticsearch se respeta el punto. Es transparente: la API es siempre la de Micrometer.
Esto es lo que diferencia tener observabilidad runtime de tener observabilidad útil al negocio. “El servicio funciona” vale poco a nivel directivo; “se procesaron X pedidos y Y fueron rechazados” se entiende solo y se grafica en un dashboard sin construir nada nuevo.
Profile condicional para no exportar en local
Cuando se trabaja en local, no interesa que la aplicación esté intentando exportar a http://otel-collector:4318 cada vez que arranca un test o un main. Las propiedades de OTel se separan en un application-otel.yml que solo se activa con el profile otel.
En docker-compose.yml, las apps arrancan con SPRING_PROFILES_INCLUDE=otel. En el IDE en local, no. Listo.
Es trivial cuando se lee, pero ahorra horas de “por qué mis tests de integración van tan lentos” cuando todavía no se ha caído en que cada uno está intentando hablar con un Collector que no existe.
05 — Lo que se ve cuando se manda una petición
Una vez todo está montado, mandar un POST /orders produce esta cascada de spans, todos con el mismo trace_id:
| Span | Servicio | Tipo |
|---|---|---|
http post /orders | order-api | Server (root) |
orders.created send | order-api | Producer (Kafka) |
orders.created process | order-processor | Consumer (Kafka) |
orderConsumer process | order-processor | Internal |
orders.processed send | order-processor | Producer (Kafka) |
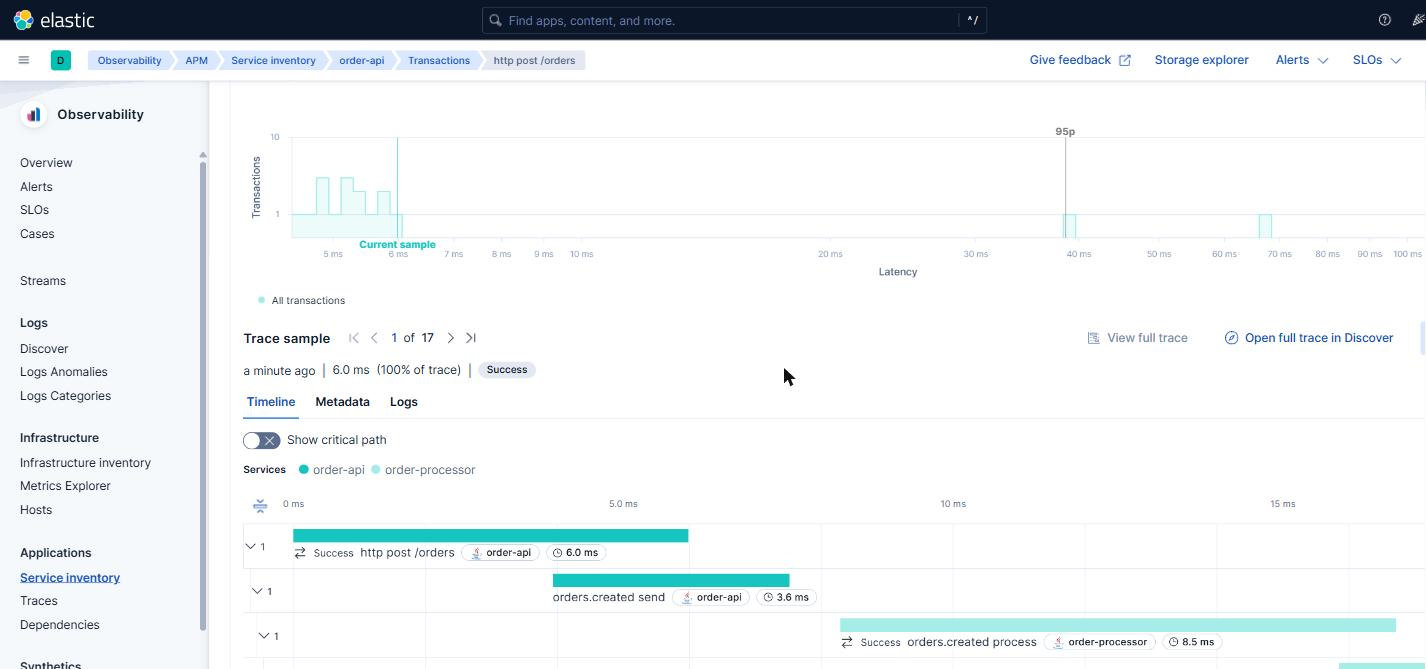
Cinco spans, dos JVMs, un broker Kafka en medio, una base de datos por debajo. Todos comparten el mismo trace_id. Esa es la prueba de que todo el ejercicio vale la pena: ahora se puede seguir el camino completo de una petición a través del sistema, aunque haya saltado de proceso, aunque haya pasado por Kafka, aunque haya esperado en una cola.
Todos los logs emitidos durante ese flujo llevan ese mismo trace_id en el MDC. Filtrando por él en Kibana se ve todo lo que pasó durante la vida de esa petición, en orden cronológico, en los dos servicios a la vez.
A partir de aquí el post tiene dos secciones paralelas. El mismo demo arrancado contra dos stacks distintos: ELK por un lado, Tempo + Loki + Prometheus + Grafana por el otro. Las apps Java no cambian. Lo que cambia es el destino al que el Collector exporta.
El demo en GitHub trae los dos overlays:
# ELK
docker compose -f docker-compose.yml -f docker-compose.elk.yml up -d
# Grafana
docker compose -f docker-compose.yml -f docker-compose.grafana.yml up -dMutuamente excluyentes (chocan en los puertos OTLP del Collector). En la sección 08 vemos cuál es la única diferencia real entre los dos.
06 — Backend A: ELK con EDOT Collector
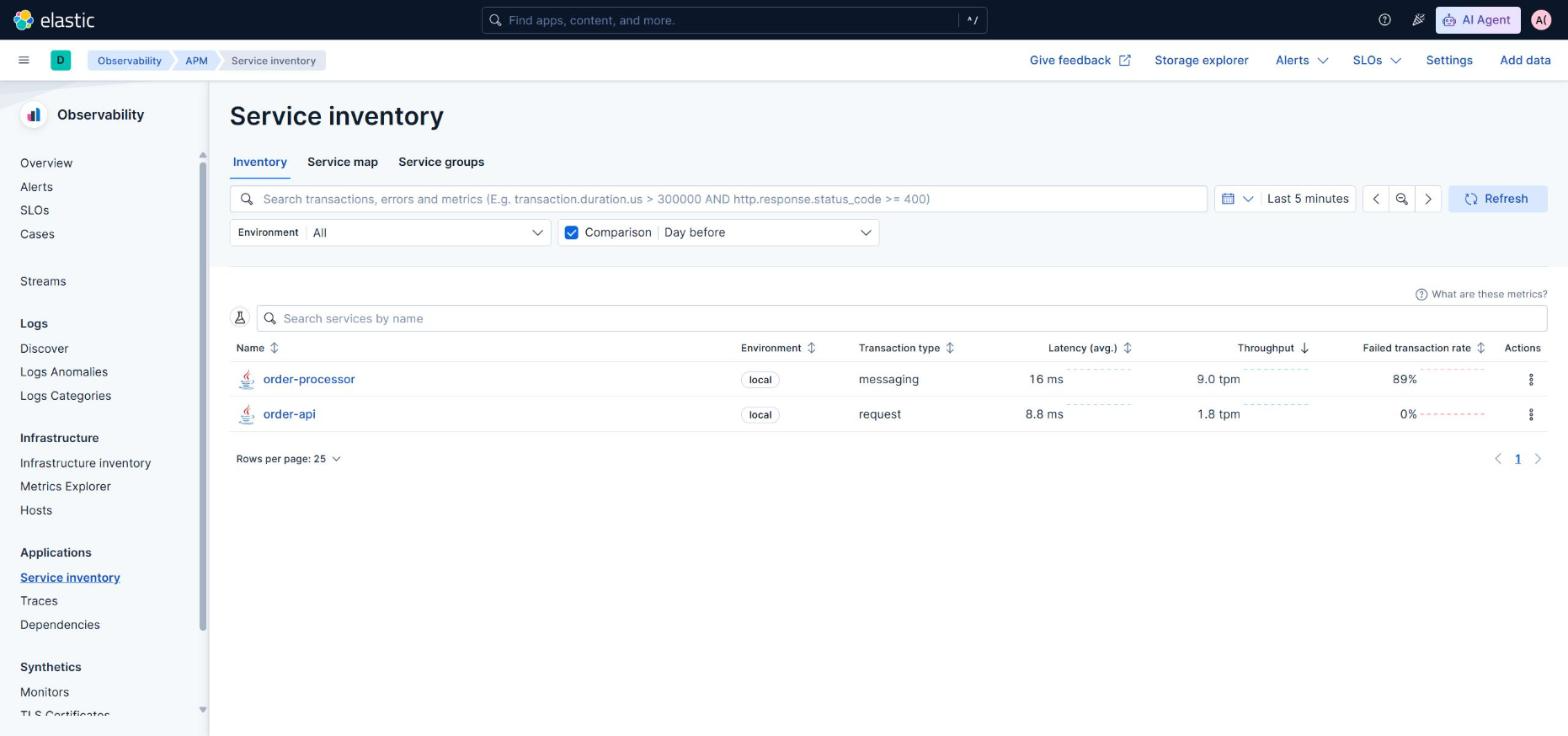
Apps emitiendo OTLP, un Collector como agregador, Elasticsearch + Kibana detrás. La parte que diferencia este stack del Collector OSS es la distribución EDOT (Elastic Distribution of OpenTelemetry): un Collector normal con dos componentes añadidos por Elastic que hacen que Kibana entienda los datos OTel como “transacciones APM” en lugar de spans genéricos.
Con EDOT, la pestaña Observability → APM de Kibana se llena sola: inventario de servicios, latencias, throughput, top errores, drilldown a un trace concreto, correlación trace ↔ log en un mismo panel. Sin construir nada.
El Service Map (grafo de dependencias entre servicios) es la única pieza que requiere licencia Platinum. El resto funciona con basic.
Los dos componentes que EDOT añade sobre el Collector OSS:
- El processor
elasticapm: enriquece los spans con atributos que la pestaña APM de Kibana espera (cosas comotransaction.type,processor.event,transaction.duration.us). Esto es lo que hace que Kibana entienda los datos como “transacciones APM” en lugar de spans genéricos. - El connector
elasticapm: convierte spans en métricas pre-agregadas (latencias, throughput, errores por servicio) y las publica en índices que la pestaña APM consume directamente.
Sin estos dos componentes, los datos OTel llegarían a Elasticsearch igualmente, pero solo se verían en Discover como documentos crudos. La pestaña APM no se enteraría.
La configuración del Collector cambia bastante respecto al vanilla. Las apps no — siguen enviando OTLP a otel-collector:4318 como antes:
receivers:
otlp:
protocols:
grpc: { endpoint: 0.0.0.0:4317 }
http: { endpoint: 0.0.0.0:4318 }
processors:
memory_limiter:
check_interval: 1s
limit_mib: 512
batch:
timeout: 2s
elasticapm: {}
# Enriquece las métricas de Micrometer (JVM heap, GC, threads) con los
# atributos que la pestaña APM Metrics de Kibana espera. Sin este
# processor, las métricas existen en `metrics-*` pero la pestaña Metrics
# se queda vacía porque Kibana espera el formato del APM Java agent
# legacy (`metricset.name: app`).
transform/apm-metrics:
metric_statements:
- context: datapoint
conditions:
- resource.attributes["telemetry.sdk.name"] == "io.micrometer"
statements:
- set(attributes["metricset.name"], "app")
- set(attributes["processor.event"], "metric")
connectors:
elasticapm: {}
exporters:
elasticsearch/otel:
endpoints: ["${env:ELASTICSEARCH_URL}"]
user: "${env:OTEL_COLLECTOR_USERNAME}"
password: "${env:OTEL_COLLECTOR_PASSWORD}"
mapping:
mode: otel
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, elasticapm, batch]
exporters: [elasticapm, elasticsearch/otel]
metrics/intake:
receivers: [otlp]
processors: [memory_limiter, transform/apm-metrics, batch]
exporters: [elasticsearch/otel]
metrics/aggregated:
receivers: [elasticapm]
exporters: [elasticsearch/otel]
logs:
receivers: [otlp]
processors: [memory_limiter, elasticapm, batch]
exporters: [elasticsearch/otel]Lo importante de esta configuración:
mapping.mode: otelen el exporter. Le dice a Elasticsearch que use el mapping OTel nativo, en vez del mapping ECS legacy.- El
elasticapmconnector aparece como receiver del pipelinemetrics/aggregated. Por ahí entran las métricas pre-agregadas (latencias, throughput, errores por servicio) que rellenan la pestaña APM Services/Transactions. - El processor
transform/apm-metricsaplicado al pipelinemetrics/intaketraduce las métricas Micrometer a la convención que la pestaña APM Metrics de Kibana espera. Más sobre esto justo abajo.
El mapeo que falta: Micrometer vs OTel semantic conventions
Spring Boot 4 emite las métricas JVM vía Micrometer. La pestaña APM Metrics de Kibana, en cambio, espera la convención semántica de OpenTelemetry para Java (heredada del Elastic APM Java agent legacy). Las dos convenciones se parecen pero no son la misma cosa: nombres distintos, atributos distintos, valores distintos en los enums. Resultado: si exportas Micrometer “tal cual” a Elasticsearch, la pestaña APM Metrics aparece vacía o con paneles rotos, aunque los datos sí están en metrics-*.
El fix vive en el processor transform/apm-metrics y es esto:
transform/apm-metrics:
metric_statements:
- context: resource
conditions:
- attributes["telemetry.sdk.name"] == "io.micrometer"
statements:
- set(attributes["agent.name"], "opentelemetry/java")
- set(attributes["service.framework.name"], "org.springframework.boot")
- set(attributes["service.instance.id"], attributes["service.name"]) where attributes["service.instance.id"] == nil
- set(attributes["host.name"], attributes["service.name"]) where attributes["host.name"] == nil
- context: datapoint
conditions:
- resource.attributes["telemetry.sdk.name"] == "io.micrometer"
statements:
- set(attributes["metricset.name"], "app")
- set(attributes["processor.event"], "metric")
- set(attributes["jvm.memory.type"], "heap") where attributes["area"] == "heap"
- set(attributes["jvm.memory.type"], "non_heap") where attributes["area"] == "nonheap"
- set(attributes["jvm.memory.pool.name"], attributes["id"]) where attributes["id"] != nil
- set(attributes["jvm.thread.state"], attributes["state"]) where attributes["state"] != nil
# Renombres de métricas (cada bloque es un metric.name → otro)
- context: metric
conditions: [name == "process.cpu.usage"]
statements: [set(name, "jvm.cpu.recent_utilization")]
- context: metric
conditions: [name == "jvm.memory.max"]
statements: [set(name, "jvm.memory.limit")]
- context: metric
conditions: [name == "jvm.memory.usage.after.gc"]
statements: [set(name, "jvm.memory.used_after_last_gc")]
- context: metric
conditions: [name == "jvm.classes.loaded"]
statements: [set(name, "jvm.class.count")]
# threads.live + threads.daemon → un único jvm.thread.count con dimensión
- context: datapoint
conditions: [metric.name == "jvm.threads.daemon"]
statements: [set(attributes["jvm.thread.daemon"], true)]
- context: datapoint
conditions: [metric.name == "jvm.threads.live"]
statements: [set(attributes["jvm.thread.daemon"], false)]
- context: metric
conditions: [name == "jvm.threads.live" or name == "jvm.threads.daemon"]
statements: [set(name, "jvm.thread.count")]Lo que aprendí montando este bloque y que no había leído en ningún sitio:
-
El “agent” se detecta por resource attribute, no por la métrica. Sin
agent.name: opentelemetry/java, Kibana enseña “Runtime metrics not available for this Agent / SDK type”, incluso si las métricas existen. Lo curioso: este atributo a veces se infiere de las traces, así que un servicio con muchos traces HTTP funciona out-of-the-box y otro con solo traces de mensajería no — son inconsistencias del propio Kibana. -
service.instance.idyhost.namedeben venir en la resource o las columnas de Kibana muestran(null). Las apps las pueden poner viaOTEL_RESOURCE_ATTRIBUTES, pero no se expande$HOSTNAMEen docker-compose. Aquí las inyectamos en el Collector usandoservice.namecomo fallback — en producción saldrán del pod/host real. -
El enum del área de memoria difiere: Micrometer usa
nonheap(sin guion bajo), Kibana esperanon_heap. Por eso se normaliza explícitamente. -
Algunas métricas que Micrometer emite como contadores separados Kibana las espera como una única métrica con dimensión. Es el caso de
jvm.threads.live+jvm.threads.daemon→jvm.thread.countcon atributojvm.thread.daemon: true/false. -
Una vez Elasticsearch fija el tipo de una métrica en su mapping (gauge / counter), no cambia. Si renombras una métrica counter a un nombre que después quieres que sea gauge, el mapping antiguo persiste y los paneles fallan con
argument of [AVG(...)] must be ... type [counter_double]. Solución:DELETE /_data_stream/metrics-...y dejar que se recree con el tipo nuevo.
Con este bloque, la pestaña APM Metrics renderiza JVM heap, GC, threads, classes loaded y memory pools en ambos servicios. Sin él, está vacía.
Observabilidad sobre la BBDD y el broker
Las apps emiten traces y métricas de cliente. Pero la BBDD y el broker tienen vida propia y son piezas igual de críticas — no las ves desde dentro de la app.
El EDOT Collector incluye un postgresqlreceiver que se conecta directamente al servidor Postgres y extrae 19 métricas dimensionales: conexiones activas, commits, rollbacks, blocks read, bgwriter, db size, index scans, table vacuum. Se configura con cuatro líneas en el config del Collector:
receivers:
postgresql:
endpoint: postgres:5432
username: ${env:POSTGRES_USER}
password: ${env:POSTGRES_PASSWORD}
databases: [orders]
collection_interval: 30sLas métricas aparecen en su propio data stream (metrics-postgresqlreceiver.otel-default) y son perfectamente filtrables en Discover por data_stream.dataset: postgresqlreceiver.otel. Con esto el dashboard de salud de la BBDD se monta en cinco minutos en Lens.
Para Kafka, las cosas no son tan limpias. Las apps ya emiten todo lo que necesitas del lado cliente: kafka.producer.* y kafka.consumer.* (throughput, latencias de commit, eventos de rebalance, conexiones, ~50 métricas). Para métricas a nivel de broker (request handlers, ISR, partitions count, log size) la única opción limpia hoy es montar un JMX exporter como sidecar, porque ni el EDOT 9.3.4 incluye kafkametricsreceiver ni el jmx receiver del contrib está soportado (está deprecado). En la demo no lo incluimos para mantener el docker-compose corto; en producción es un sidecar más.
Para que Kibana muestre los contenedores en la pestaña Infrastructure → Containers (lo que en otros stacks sería “host inventory”), el Collector incluye también el receiver docker_stats:
docker_stats:
endpoint: unix:///var/run/docker.sock
collection_interval: 30sY al servicio se le monta el socket de Docker en read-only:
otel-collector:
volumes:
- /var/run/docker.sock:/var/run/docker.sock:roLas métricas viajan a Elasticsearch y son explorables en Discover.
Una matización honesta que descubrí intentando llevarlas a la pestaña Infrastructure inventory de Kibana. El primer instinto es: “estas métricas son de contenedor, las debería ver en la waffle map de Observability → Infrastructure”. El problema es que esa UI no soporta datos OTel-native todavía en 9.3.4. La razón no es el nombre del índice — es que la lista de campos que la UI consulta está hardcoded a la integración Metricbeat:
| La UI espera | Datos OTel-native emiten |
|---|---|
docker.container.id | container.id (semconv) |
docker.cpu.total.pct | container.cpu.utilization |
docker.memory.usage.pct | container.memory.percent |
metricset.module: "docker" | (no aplica en OTel) |
Forzarlo implicaría duplicar cada métrica con el nombre Metricbeat — reimplementar Metricbeat dentro del Collector. No tiene sentido. Elastic está incorporando OTel como parte central del stack y el soporte OTel-native para Infrastructure UI está en su roadmap, pero todavía no en 9.3.4. Es un caso muy de transición: la integración profunda con OTel ya está hecha para APM, Logs y Traces; Infrastructure aún no.
La vía idiomática para visualizar métricas de infra con datos OTel-native hoy es un dashboard Lens propio, que es exactamente lo que veremos en la siguiente sección.
Dashboard pre-provisionado al arrancar
La pestaña APM Metrics te da los gráficos de cada servicio Java. Para vistas que crucen capas — “DB connections + record send rate + consumer lag” en una misma pantalla — hace falta construir un dashboard. Eso es lo que diferencia tener observabilidad de tenerla usable.
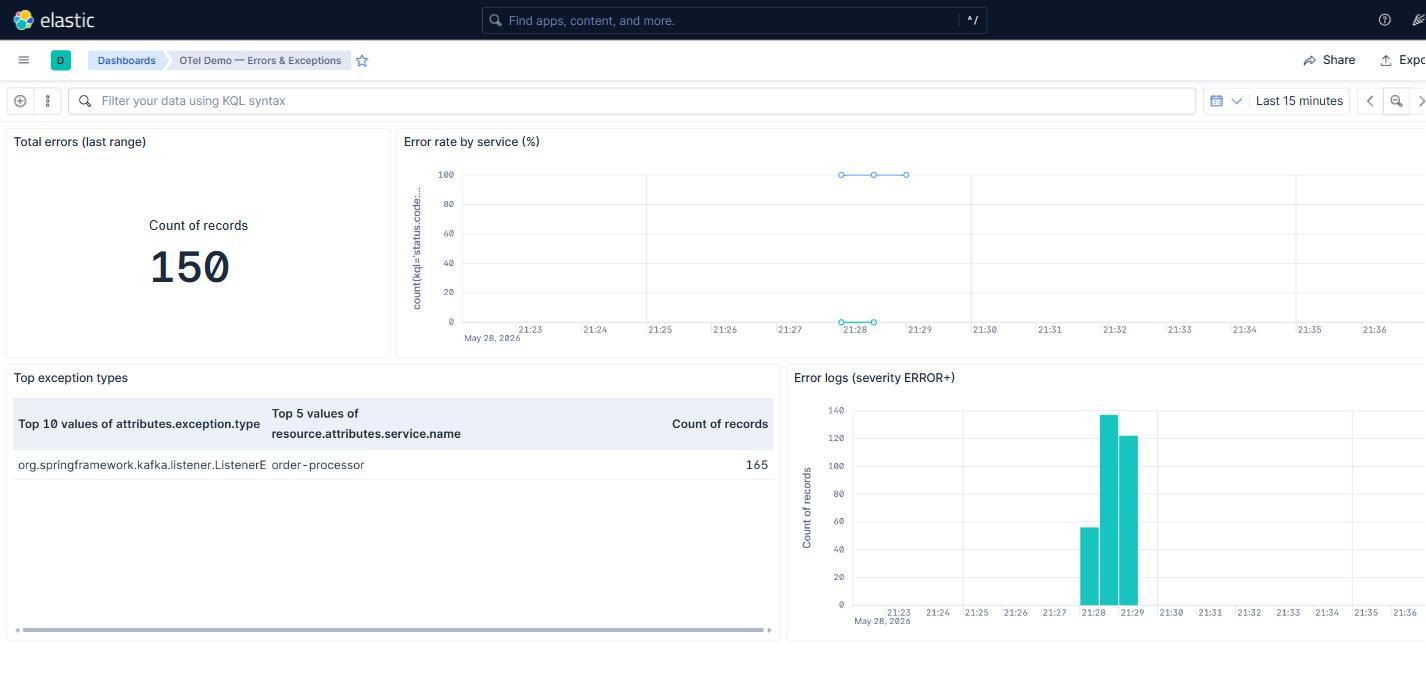
En la demo todo eso se hace solo. El servicio kibana-setup (que ya crea las data views al arrancar) importa además dos dashboards pre-construidos. El primero, “OTel Demo — Infra (Postgres + Kafka)”: seis paneles Lens con conexiones activas, commits/rollbacks, blocks read, DB size, producer record send rate por servicio y consumer lag máximo. El segundo, “OTel Demo — Errors & Exceptions”, complementa la pestaña built-in: total de errores, error rate por servicio, top exception types y stream de logs ERROR con stack trace al lado. Las definiciones viven en elk/kibana/dashboards.ndjson y elk/kibana/errors-dashboard.ndjson, y ambos se montan en el contenedor del setup:
kibana-setup:
volumes:
- ./elk/kibana/setup.sh:/setup.sh:ro
- ./elk/kibana/dashboards.ndjson:/dashboards.ndjson:ro
- ./elk/kibana/errors-dashboard.ndjson:/errors-dashboard.ndjson:roEl script lo importa con ?overwrite=true (idempotente). Cuando clonas el repo y haces docker compose up, el dashboard “OTel Demo — Infra” aparece solo en Kibana → Dashboards. Sin pasos manuales, sin recordar qué arrastrar a qué eje.
Para iterar el dashboard: editas en Kibana, lo exportas desde Stack Management → Saved Objects, reemplazas el NDJSON del repo. Próximo up arranca con la nueva versión. Es el patrón “GitOps para observabilidad” — la configuración de los dashboards viaja con el código.
Una piedra con la que tropecé: network.host en Elasticsearch
Elasticsearch 9.x por defecto solo escucha en localhost dentro del contenedor. Si arrancas otro contenedor (Kibana, el EDOT Collector) en la misma red Docker y le hablas a http://elasticsearch:9200, te devuelve “Connection refused” hasta que añades esto al elasticsearch.yml:
network.host: 0.0.0.0Trivial cuando se sabe. Una hora perdida cuando no se sabe. Lo dejo aquí por si le ahorra el trago a alguien.
Con todo arrancado, en Kibana → Observability → APM los dos servicios aparecen solos. Click en order-api, click en http post /orders, click en el sample trace y aparece el waterfall completo de los cinco spans cruzando ambas JVMs. La correlación trace ↔ log está en una pestaña dentro del mismo trace: tres logs del flujo, filtrados por trace_id, en orden cronológico. Sin construir nada.
Y los dos dashboards pre-cargados acompañan a la pestaña APM built-in con vistas que cruzan capas. Por ejemplo el de errores agrupa por exception type y la stream de logs ERROR al lado:
07 — Backend B: Tempo + Loki + Prometheus + Grafana
Las mismas apps, el mismo Collector como agregador, otros backends detrás. Cuatro componentes en vez de dos, todos OSS:
- Tempo para trazas. OTLP nativo en
:4317/:4318, motor TraceQL para consultas. Además, sumetrics_generatorpuede emitir métricas pre-agregadas a partir de los spans (latencia, error rate, edges del grafo de servicios) y push’arlas a Prometheus. - Loki para logs. Receiver OTLP nativo (desde 3.0). Necesita
allow_structured_metadata: trueen su config — sin eso los atributos OTel del log (trace_id, severity_text, code_filepath) se descartan en ingesta y los logs quedan como JSON crudo. - Prometheus para métricas. Tiene OTLP receiver nativo desde 2.55, activable con el flag
--web.enable-otlp-receiver. No necesitas Mimir ni cosas más grandes para un demo o un volumen moderado. - Grafana como UI única para los tres datasources.
La pestaña equivalente a “APM” de Kibana aquí no es built-in: se construye con un dashboard Lens propio. Eso es trabajo extra, pero también es el patrón “observability as code” — el dashboard vive en Git y se versiona con el resto del repo. En el demo lo dejamos precargado: Grafana arranca con tres dashboards listos (APM/JVM/transactions, Errors & Exceptions, Infra Postgres + Kafka) sin tocar la UI.
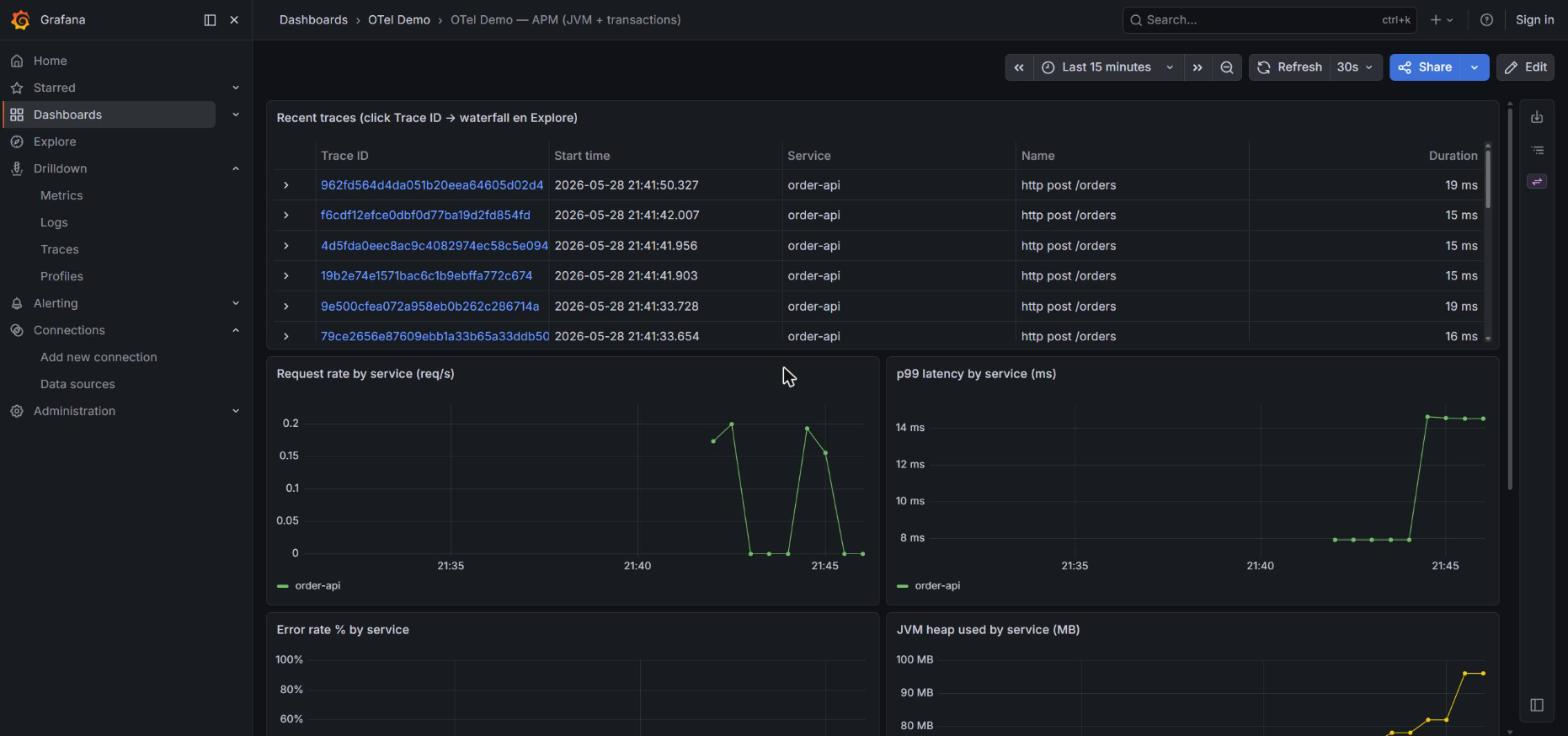
Donde Grafana saca pecho frente a ELK es en el Service Map: el processor service-graphs del metrics_generator de Tempo emite las edges del grafo como métricas, y Grafana las dibuja como nodos enlazados (user → order-api → Kafka:orders.created → order-processor → Kafka:orders.processed). Sin licencias.
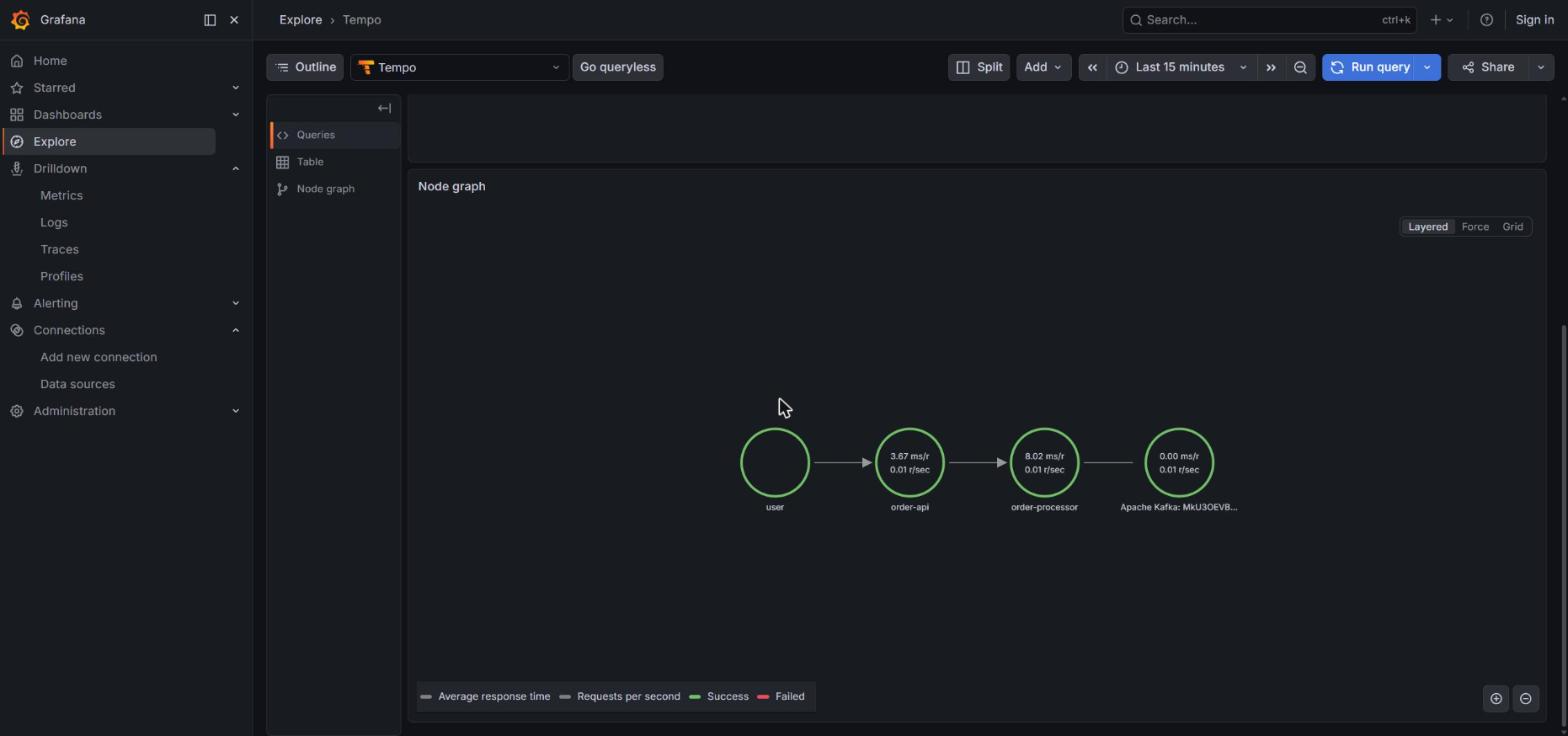
Aparte del dashboard, hay tres apps “Drilldown” en el menú lateral de Grafana — Metrics, Logs y Traces — que son a Prometheus/Loki/Tempo lo que Discover es a Kibana: exploración sin escribir queries. Las tres detectan automáticamente datasources y arrancan con paneles auto-generados por servicio. Útil cuando aún no sabes qué buscar.
La correlación cross-señal funciona pero se configura. El datasource de Loki en el provisioning lleva un bloque derivedFields que extrae trace_id de los logs y lo enlaza a Tempo; el de Tempo lleva tracesToLogsV2 apuntando a Loki; Prometheus expone exemplars que enlazan métricas a las trazas que las originaron. Una vez activado, cliquear en un log abre el trace; cliquear en un span abre los logs del span. El comportamiento es el mismo que en Kibana — la diferencia es que Kibana lo trae configurado y aquí se versiona en un YAML.
Donde Grafana hoy pide más trabajo:
- Cuatro componentes operativos en lugar de uno. Distintos lenguajes de configuración, distintos modelos de almacenamiento, distintos backups.
- Tres lenguajes de consulta distintos: TraceQL, LogQL, PromQL. El equipo aprende los tres.
- No hay equivalente built-in a la pestaña Errors UI de Kibana APM. Los errores existen (los spans con
STATUS_CODE_ERRORyattributes.exception.typeestán en Tempo), pero hay que construir el panel — que es lo que hacemos en el dashboard custom de errores del demo.
08 — Lo único que cambia entre los dos
El argumento operativo del post: las apps no se enteran de cuál de los dos backends hay detrás. Mismo pom.xml, mismo application.yml, mismo OTEL_RESOURCE_ATTRIBUTES. Mismos handlers, mismas anotaciones, mismo Logback appender.
Lo único que cambia es un único fichero: la configuración del Collector. Y dentro de ese fichero, casi todo se mantiene — solo cambia el bloque exporters y cómo se enchufan en los pipelines.
Lado a lado, los exporters de cada stack:
# ELK
exporters:
elasticsearch/otel:
endpoints: ["${env:ELASTICSEARCH_URL}"]
user: "${env:OTEL_COLLECTOR_USERNAME}"
password: "${env:OTEL_COLLECTOR_PASSWORD}"
mapping:
mode: otel
# Grafana
exporters:
otlp/tempo:
endpoint: tempo:4317
tls:
insecure: true
otlphttp/loki:
endpoint: http://loki:3100/otlp
tls:
insecure: true
otlphttp/prometheus:
endpoint: http://prometheus:9090/api/v1/otlp
tls:
insecure: trueLos receivers (OTLP, postgresql, docker_stats) son idénticos. Los processors (memory_limiter, resource, batch) también. La única simplificación en el lado Grafana es que no necesita elasticapm ni transform/apm-metrics — esos eran adaptadores específicos para que Kibana entendiera los datos como APM.
Si mañana decides cambiar de proveedor: tocas ese fichero, no las apps. Si mañana quieres mandar las trazas a Datadog, las métricas a Mimir y los logs a Loki, basta con otros tres bloques exporters y un repintado de los pipelines. Las apps siguen emitiendo OTLP sin enterarse.
Esa es la promesa real de OpenTelemetry, y se demuestra en menos de 20 líneas de YAML.
Y se nota visualmente: el mismo demo, otro stack, otra UI, las mismas señales con la misma fidelidad. El dashboard de errores en Grafana cuenta la misma historia que el de Kibana — el código no cambia:
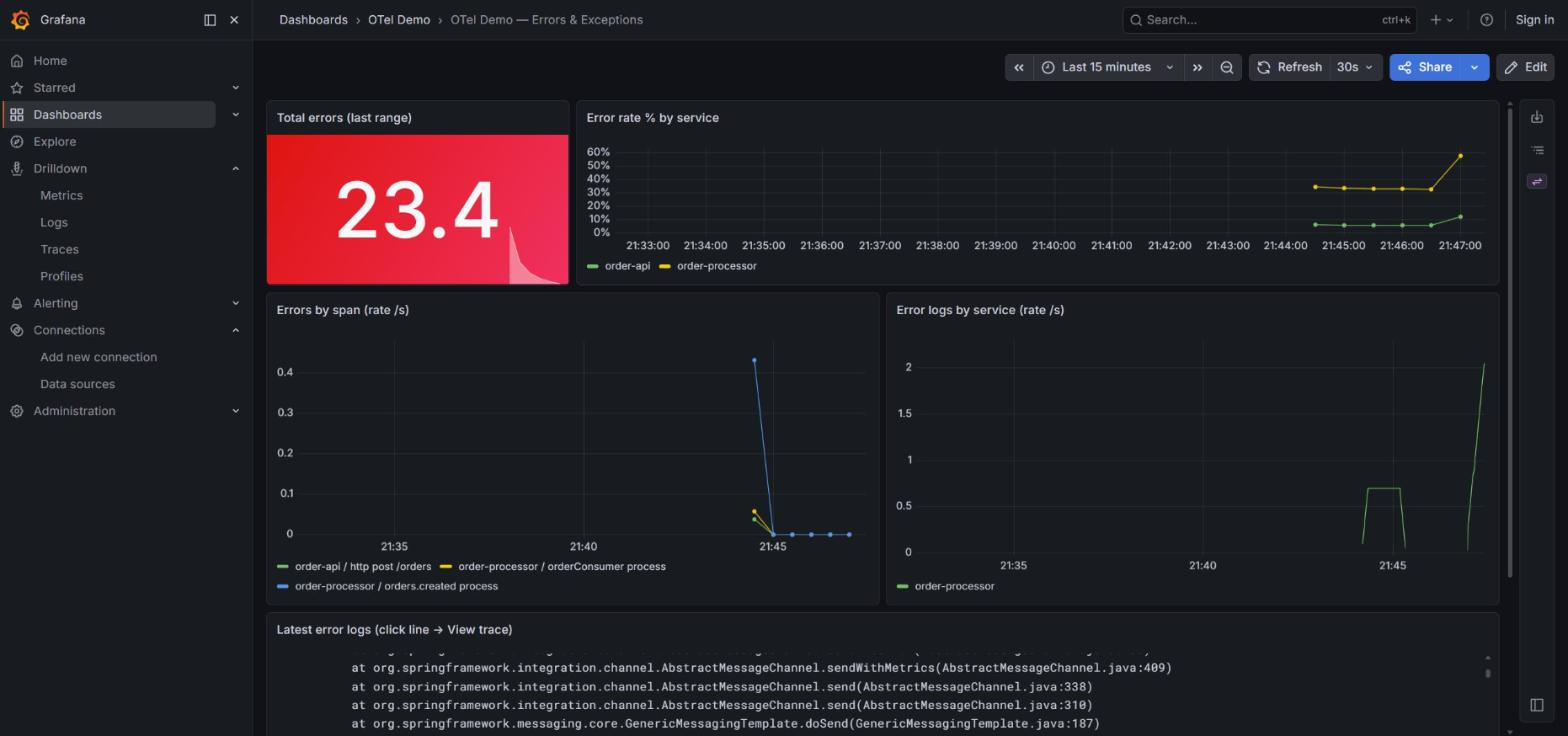
09 — Lo que aún no me convence
Lo que el setup aún no resuelve, en ambos stacks por igual:
Configuración del Collector cuando crece. Los YAML de arriba están simplificados. En producción acaba habiendo varios receivers, filtros por servicio, transformaciones de atributos, sampling tail-based, batching, retry con cola persistente, redirección de pipelines distintos por tipo de dato. Es mucho YAML, sin tipos, sin tests sencillos. La gobernanza del Collector como pieza de infraestructura crítica todavía es algo que estoy buscando cómo abordar bien.
La propagación consumer-side de Spring Cloud Stream Kafka. Hoy hay que hacerla a mano (sección 04). Es un parche, no una solución. Cuando Spring Cloud Stream cierre esta brecha el bloque de extracción manual sobra. Pero hasta entonces, es la cuota que se paga por la decisión de no usar el Java agent.
El mapeo Micrometer ↔ OTel semconv (solo afecta a ELK). Es un bloque de OTTL de unas 30 líneas en el Collector. Mientras Spring siga emitiendo via Micrometer y Kibana siga esperando OTel semconv, el mapeo será necesario. Es estable, pero feo: cada vez que actualizas Spring Boot toca verificar que no se rompe.
Métricas de broker Kafka. Hoy no hay receiver OTel-nativo. Para vigilar el broker desde el mismo pipeline hay que añadir un JMX exporter sidecar. Es trabajo de plataforma que sale del scope de la app pero no del scope del observability platform.
Infrastructure UI con datos OTel-native, en ambos. Kibana 9.4.1 todavía no soporta la pestaña Infrastructure → Hosts/Containers con OTel-native — la UI espera campos Metricbeat. En Grafana la pestaña equivalente (la subapp Infrastructure dentro de un APM service) depende del receiver hostmetrics corriendo cerca del servicio, lo cual no encaja con un setup de Docker Compose con Collector central. En K8s real debería funcionar, gracias al k8sattributesprocessor — pero el demo está con Docker Compose.
Patrones que no son HTTP ni Kafka. @Scheduled se traza automáticamente con el starter pero el span se nombra de manera genérica — conviene renombrarlo y, si dentro hay un loop sobre muchas entidades, abrir un sub-span por iteración a mano. SSE: como es HTTP, el starter abre un span por conexión, pero ese span dura tanto como el stream — minutos o horas — y los eventos individuales no aparecen por separado salvo que crees span hijo en el callback que escribe cada chunk. WebSocket: el handshake (HTTP upgrade) se traza solo; los mensajes individuales — @MessageMapping, frames STOMP — no, y requieren @Observed o un interceptor. Spring Batch traza job y step, los chunks rara vez. Ninguno bloquea pero todos exigen “configurar a mano” en algún grado.
Ninguno es bloqueante. Lo que sí hace este blog es desmentir la idea de que basta con añadir el starter — el trabajo de la sección 04 sigue existiendo.
10 — Para cerrar
El cambio importante de OpenTelemetry es conceptual, no técnico. Antes, decidir cómo instrumentar una aplicación significaba elegir vendor antes de empezar y atarse. Ahora la decisión es otra: se instrumenta con OpenTelemetry, se elige backend después, y la decisión del backend puede cambiar sin tocar el código de la aplicación.
Este post deliberadamente no recomienda uno sobre el otro. ELK te lleva más rápido a una pestaña APM completa sin construir nada — a cambio de licencia para piezas como el Service Map. Grafana te da Service Map gratis y un ecosistema OSS completo — a cambio de operar cuatro componentes y construir tú lo que en ELK viene de serie. Las dos opciones son válidas y la decisión razonable es operativa: qué conoce el equipo, qué presupuesto hay, qué tienes ya rodando para otras cosas. Lo que no debería pesar en esa decisión es el código de las apps, porque el código no cambia.
El demo está en github.com/ujados/otel-observability-demo. Tiene tres docker-compose: el base con el Collector vanilla escribiendo a consola, el override elk.yml con EDOT + Elasticsearch + Kibana, y el override grafana.yml con Tempo + Loki + Prometheus + Grafana. Clónalo, arráncalo en uno cualquiera de los dos backends, manda peticiones, observa el trace_id propagado de extremo a extremo. Luego cambia de override y vuelve a hacerlo — sin tocar las apps. Ver esa portabilidad en vivo se entiende mucho mejor que leyéndola.